Five years ago, deploying a customer-service chatbot was a competitive edge. In 2026, it is closer to table stakes — and the conversation among small-business owners has shifted from “should we use one?” to “how do we know ours is actually working?” That second question is harder, because most teams launch a bot, watch the deflection numbers tick up, and never establish what “good” looks like for a company their size.
This guide lays out the benchmarks that matter, where the industry is heading, and how a small team can read its own numbers without a data-science department.
Why the ground shifted
The adoption curve is no longer a forecast — it is the present. Gartner has projected that chatbots will become the primary customer-service channel for roughly a quarter of organizations, and its more recent surveys show self-service and live chat overtaking traditional phone and email as the most valuable service technologies. On the supply side, McKinsey’s State of AI research found that the majority of organizations now use generative AI regularly in at least one business function, with service operations consistently among the most common.
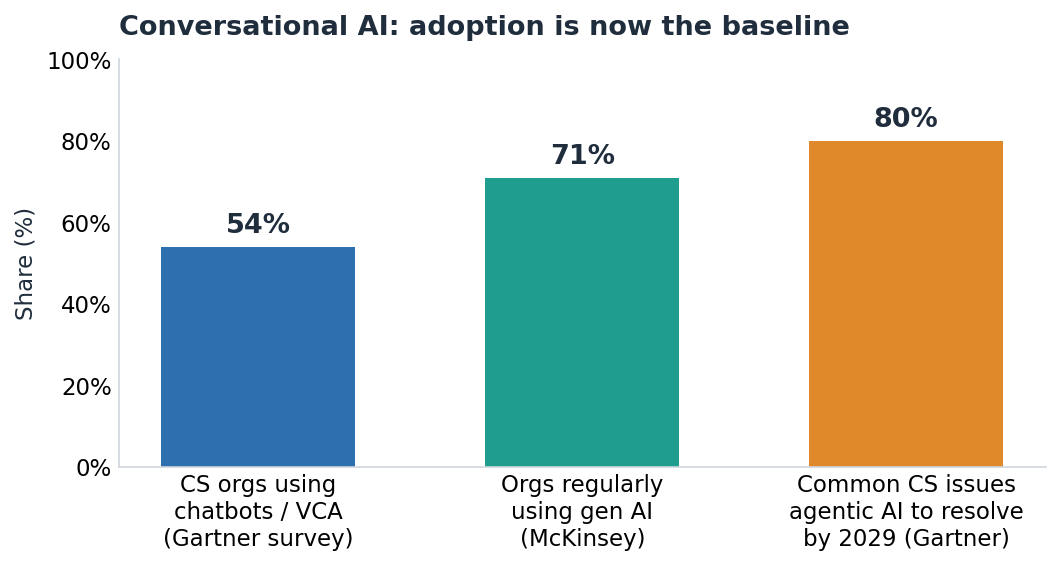
Figure 1 — Adoption is now the baseline, not the bet. Sources: Gartner; McKinsey State of AI.
What changed is not just availability but capability. The first generation of rule-based bots could only follow scripted decision trees. The current generation, built on large language models, can interpret messy phrasing, hold context across a conversation, and hand off cleanly to a human when it hits its limits. For a small business, that means a bot is no longer a deflection wall — it is a first responder.
The small-business angle
Large enterprises measure chatbots against contact-center cost models. Small businesses have a different reality: the “support team” is often one or two people, sometimes the founder. The value of conversational AI here is less about shaving cents off millions of tickets and more about buying back hours — answering the same shipping question for the fortieth time so a human can handle the one customer who is genuinely upset.
That difference should shape which numbers you track.
The five benchmarks that actually matter
Forget vanity metrics like “total messages handled.” The benchmarks below tell you whether your bot is helping customers or quietly annoying them.
1. Containment (or resolution) rate
This is the share of conversations the bot fully resolves without a human. It is the headline number, but it is also the easiest to game — a bot that refuses to escalate will show a high containment rate and a furious customer base. A healthy target for a well-scoped small-business bot handling FAQs, order status, and basic account questions tends to land in the 40–60% range. Push much higher and you should double-check that you are not trapping people.
2. First-contact resolution (FCR)
Of the conversations the bot contains, how many end with the customer’s problem genuinely solved on the first try? FCR is the honesty check on containment. If containment is high but FCR is low, your bot is closing tickets, not solving problems.
3. Escalation quality, not just escalation rate
A high escalation rate is not a failure. The question is whether escalations arrive with context. A good handoff passes the full conversation, the customer’s intent, and any data the bot already collected to the human agent. A bad handoff dumps the customer back to square one — which is worse than having no bot at all.
4. CSAT on bot-handled conversations
Track satisfaction separately for bot and human interactions. A one-tap thumbs-up/down at the end of a chat is enough. If bot-handled CSAT trails human CSAT by more than a small margin, your scripts or your escalation thresholds need work.
5. Time-to-first-response and after-hours coverage
For a small team, this is often the real prize. A bot that answers in seconds at 11 p.m. converts a frustrated late-night visitor into a satisfied one. Measure the share of conversations happening outside business hours — for many small e-commerce stores it is a surprisingly large slice, and it is volume your human team was never going to cover anyway.
A simple scorecard
You do not need a dashboard suite to start. The table below is a starting scorecard a one- or two-person team can maintain in a spreadsheet, reviewed monthly.
Metric | What it tells you | Reasonable starting target |
Containment rate | Workload taken off humans | 40–60% |
First-contact resolution | Whether contained tickets are truly solved | 70%+ of contained |
Escalation with context | Handoff quality | 100% of escalations |
Bot CSAT | Customer sentiment on automation | Within ~5 pts of human CSAT |
After-hours share | Coverage you gained for free | Track trend, not a fixed target |
The targets are deliberately framed as starting points, not industry law. Your category, your customers, and your bot’s scope all move these numbers.
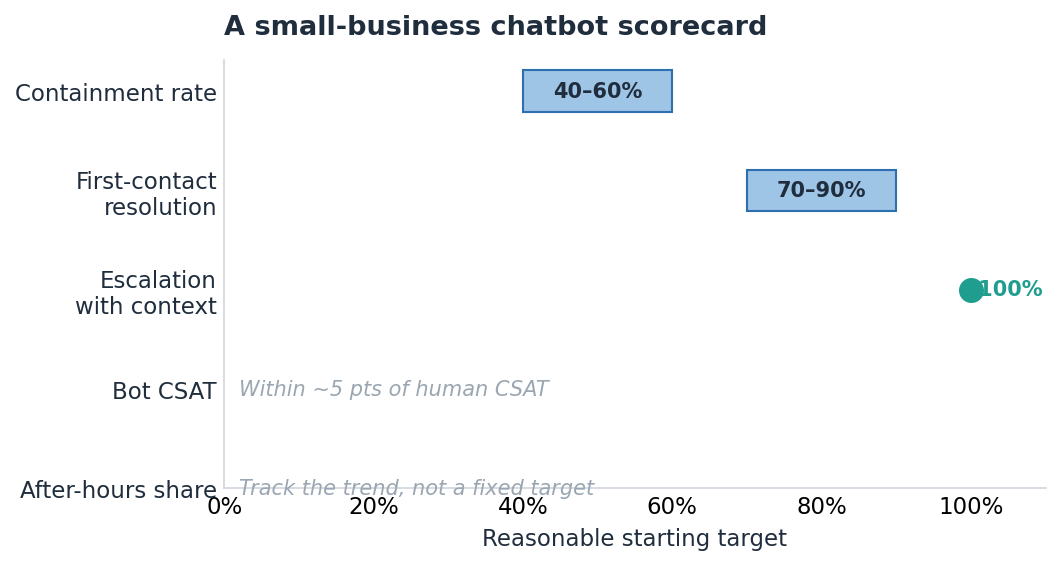
Figure 2 — The five-metric scorecard, visualized. Targets are planning starting points, not measured averages.
Reading the trend lines, not the snapshot
A single month of data is noise. The signal is in the direction of travel. Three patterns are worth watching over a quarter:
First, containment should rise as you feed the bot real questions. If it is flat, your knowledge base is stale. Second, escalation reasons should cluster. When you see the same unhandled question appear fifty times, that is a content gap you can close in an afternoon — and closing it is the single highest-leverage thing a small team can do. Third, bot CSAT should not drift down as containment rises. If it does, you are automating past the point of helpfulness.
Where this is heading
The next shift is already visible. Gartner projects that agentic AI — systems that can take actions, not just answer questions — will autonomously resolve a large majority of common customer-service issues by the end of the decade. For a small business, that means the bot stops being a question-answering layer and starts doing things: issuing the refund, rebooking the appointment, updating the shipping address.
That future raises the stakes on the benchmarks above. The more a bot can do, the more it matters that you are measuring whether it is doing the right things. Resolution without satisfaction is just faster churn.
Choosing a platform without the guesswork
The benchmarks only matter if your platform can actually report them and your bot can scope to your real use cases. Platforms vary enormously in how they handle escalation, multi-channel coverage, and analytics — and the right fit for a 200-seat contact center is rarely the right fit for a two-person store. If you are comparing options, independent, side-by-side breakdowns of features and pricing are far more useful than vendor marketing; resources like Chatbotscape exist to make that comparison less painful.
Whatever you choose, resist the temptation to judge it on launch-day novelty. Set your scorecard first, give the bot real questions for a month, and let the trend lines tell you whether it earned its place on your team.
Frequently asked questions
What is a good containment rate for a small business?
For a bot scoped to FAQs, order status, and basic account questions, 40–60% is a reasonable starting band. Treat anything dramatically higher with suspicion — it often means customers cannot reach a human, not that the bot is brilliant.
How is containment different from first-contact resolution?
Containment counts conversations handled without a human. First-contact resolution counts conversations actually solved on the first try. A bot can contain a ticket without resolving it, which is why you track both.
How long before I can trust the numbers?
Give it a full month of real customer questions before drawing conclusions, then read the quarter-long trend rather than any single month.
Do I need analytics software to measure this?
No. A one- or two-person team can maintain the five-metric scorecard in a spreadsheet, reviewed monthly. The platform should at minimum let you export conversation logs and escalation reasons.
The takeaway
Conversational AI has crossed from edge to expectation, and for small businesses the win is measured in reclaimed hours and round-the-clock coverage, not enterprise cost curves. Pick five benchmarks, watch their direction over a quarter, and fix the content gaps your escalation logs hand you. Do that, and you will be ahead of most teams — including ones with far bigger budgets.
Published: June 3, 2026




